近年来,人工智能机器学习在材料科学研究中得到了广泛的应用。通过构建的材料数据库等大数据系统进行机器学习模型训练,许多还没有实验和理论数据的化合物性质可以被预测出来,这将大大加速新材料发现及相关研究。机器学习在材料科学中的应用之一是建立结构与性能之间的关系,它试图在材料指纹(包括组成元素的特征、原子结构信息以及这些特征的任何组合)和我们感兴趣的目标属性之间建立预测关系。过去的工作中,机器学习方案的预测能力在材料的带隙、弹性模量、相稳定性、离子电导率、导热系数、熔融温度、玻璃化转变起始温度等性质有着很好的表现。
北京大学深圳研究生院新材料学院潘锋团队近年承担了国家材料基因组工程研发固态电池及关键材料的项目,构建有60多万独立晶体结构的大数据系统(www.pkusam.com)并且尝试应用人工智能机器学习的方法来加速新型材料的发现。在以往的研究中,机器学习方案的成功是基于数据库中数据的共同趋势,通过这样的共同趋势训练,开发的模型可以应用于预测大多数化合物的结构与性能的关系。这对通常的化合物是有效的、准确的,因为在材料数据库的大多数情况下,通常化合物具有规则的结构单元。然而,例外总是存在的(即使有95%的预测精度,总还有5%的例外)。潘锋团队通过对大量数据不断改良机器学习不仅能够实现高精度预测材料的结构和性能相关性(相当于发现材料的“遗传”性质),同时首次原创性着眼于这些不在预测范围的“例外”,并且通过分析这些“例外”(相当于发现材料的“变异或突变”性质),即分析远离总体趋势的异常结果,从中获得新的洞见,发现了新型的结构基元(具有正3价的银离子基团),这对基础物理化学有了一些新的认识,并在科学上开辟了新的领域。该成果“Discovering unusual structures from exception using big data and machine learning techniques”以论文形式,应邀在著名学术期刊《Science Bulletin》(64 (2019) 612–616)上以封面文章发表。


在该工作中,团队通过自主建立了一个包括HSE计算数据的材料结构数据库,并基于此通过机器学习的方法对材料结构的带隙进行学习,并展示了机器学习是如何被用来作为一种工具来挑选这些不寻常的案例,以及如何用传统的分析方法来研究这些不寻常的案例,从而拓宽已有的科学知识。在该工作中,团队只使用了相对较小的数据集进行训练,并且ML模型的总体性能与已有的工作相当,模型R2约为0.89。通过观察带隙预测模型的结果,团队从数据库约4000种化合物中确定了34种不同寻常的“例外”化合物,在具体的分析之后,其中许多化合物具有不寻常的结构或其它异常,如特殊的配位环境或氧化态,带隙相对于同族其它化合物的突然增加,或是同族不同化合物之间的不同相结构。
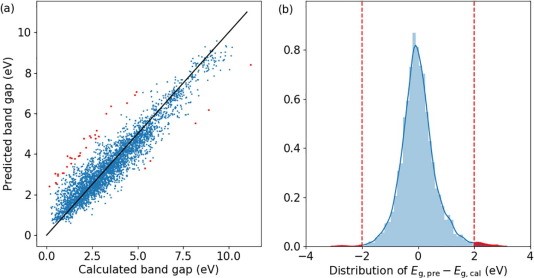
机器学习预测带隙的结果
在这些具有较大预测误差的化合物中,团队发现了具有Ag3+和O22-特殊结构的AgO2F。随后,通过与KAgO2(“正常”结构)的电子结构对比,他们发现AgO2F中不寻常的氧化态(O22-)使得O与Ag之间轨道杂化很小,带隙附近的能级主要由O原子的2p轨道贡献,带隙远小于其它含有Ag3+的化合物。这一实例证明了可以通过检查机器学习模型中的异常,从大型数据库中快速发现异常结构。

AgO2F(“异常”结构)与KAgO2(“正常”结构)的电子结构比较。AgO2F由于具有不寻常的氧化态(O22-)从而具有异常的表现
该工作由新材料学院潘锋教授和伯克利汪林望教授指导,16级研究生揭鉴澍与团队合作完成。本工作得到国家材料基因工程重点研发计划和广东省重点实验室的资金支持。
文章链接:https://www.sciencedirect.com/science/article/pii/S2095927319302014




